LizMyers.github.io
Coffee Mate (Preview)

Use Case
Problem: When my Nespresso capsules become separated from their boxes, I lose all the information about them. Solution: Use Google Home Hub to identify capsules and dispense info about them via voice.
Technologies
- Dialogflow
- Tensorflow Lite
- Firebase - database, storage, ml, cloud functions
- Auto ML on GCP - built custom model for capsule I.D. via camera
- Angular JS
- Typescript and VS Code
Status
Currently, I’m bug fixing, polishing UI, and collaborating on TF integration. The latter, is tricky b/c documentation only exists for native iOS and Android implementation. Firebase ML is in Beta and as of yet, there is no official Angular integration path.
Tensorflow
TFJS - Experiments in Chrome
TFJS01
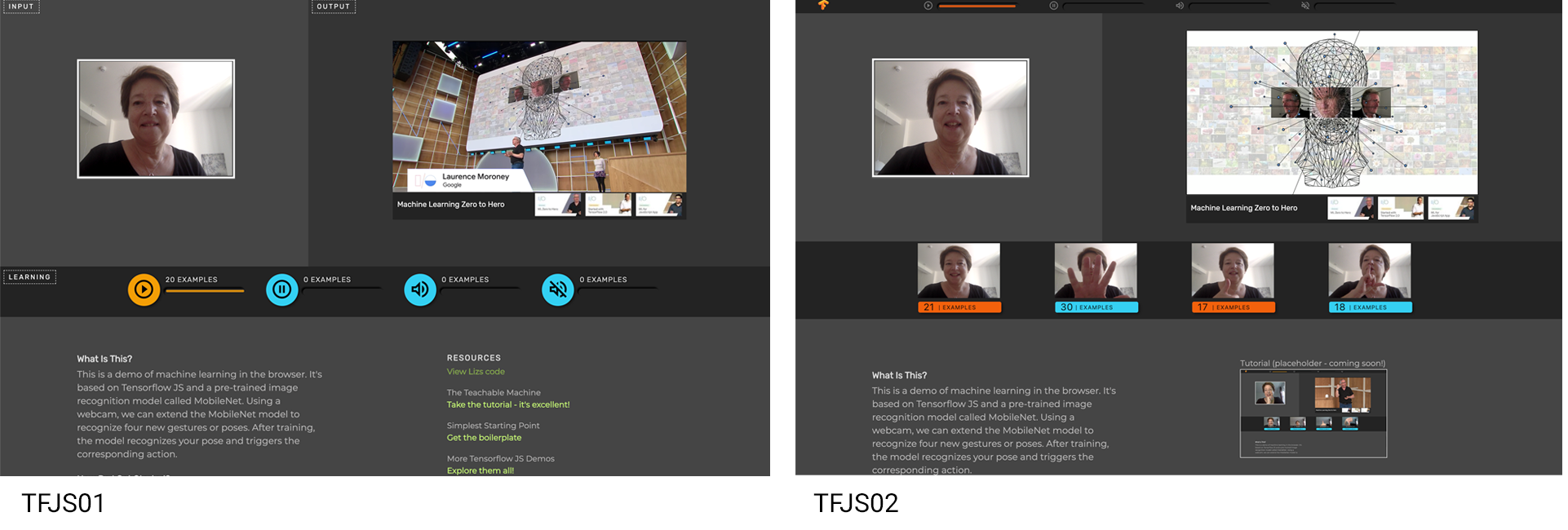
This project use the MobileNet Model for image recognition and the YouTube API for video control. In this example, the user trains the model on four gestures or poses that correspond to four video actions: play, pause, unmute, mute. While the program runs, the webcam is watching for one of the poses and responds with the corresponding action. Please note: this project is designed for Chrome on desktop/laptop. It’s best viewed in full screen mode.
TFJS02
The first version used standard video control buttons for training. In a quick usability test, I discovered the UI caused friction because the mental model is broken. Although the buttons look like real playback controls, they don’t function as such during inference. Once Tensorflow kicks in… the only way to control playback is with one of the custom gestures.
Here’s what I did to improve usability:
- Separated training and inference areas (bottom and top rows respectively)
- Implemented icons as labels rather than buttons (greyed out, single state)
- Added still images on capture - reminding users of gestures and related actions
Please note: this project is designed for Chrome on desktop/laptop. It’s best viewed in full screen mode.
AIY Voice Kit
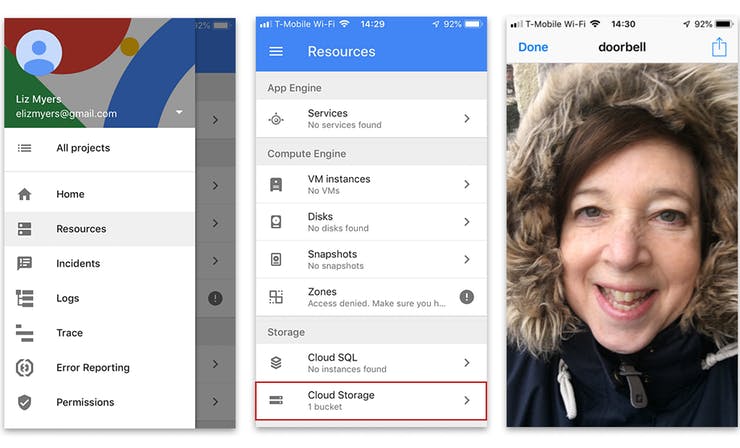
Smart Doorbell
Imagine, when someone rings your bell, it prompts the Google Assistant to greet the visitor. The Pi camera takes their picture and saves it up to the cloud for review. Once you’ve had a chance to confirm the visitors identity visually, you can ask the Assistant to open the door and let them in. A detailed tutorial is available here.
What is That?
This project adds computer vision to the voice kit, so that machines can describe what they see! Using a Raspberry Pi, Tensorflow, and Python, you can identify three classes: logos, text, and objects. A detailed tutorial is available here.